Python 学习(六)
本文共 4696 字,大约阅读时间需要 15 分钟。
1. 正则表达式
re 模块使 Python 语言拥有全部的正则表达式功能。
1). re.match函数 re.match 尝试从字符串的起始位置匹配一个模式,如果不是起始位置匹配成功的话,match()就返回none。 函数语法:re.match(pattern, string, flags=0)
函数参数说明:
pattern : 匹配的正则表达式 string : 要匹配的字符串 flags : 标志位,用于控制正则表达式的匹配方式,如:是否区分大小写,多行匹配等等。# 正则表达式import re# 在起始位置开始匹配print(re.match("www","www.baidu.com").span())# 不在起始位置开始匹配print(re.match("com","www.baidu.com")) 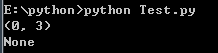
图1.png
2). 使用group(num) 或 groups() 匹配对象函数来获取匹配表达式。
- group(num=0):匹配的整个表达式的字符串,group() 可以一次输入多个组号,在这种情况下它将返回一个包含那些组所对应值的元组
- groups():返回一个包含所有小组字符串的元组,从 1 到 所含的小组号
# groupimport re# 字符串line = "Cats are smarter than dogs"# 正则匹配matchObj = re.match(r'(.*) are (.*?) .*', line, re.M|re.I)# 判断是否匹配成功if matchObj: print("matchObj.group(): ", matchObj.group()) print("matchObj.group(1): ", matchObj.group(1)) print("matchObj.group(2): ", matchObj.group(2)) passelse: print("No match!") 打印结果:

图2.png
3). re.search方法
re.search 扫描整个字符串并返回第一个成功的匹配。 函数语法:re.search(pattern, string, flags=0)
函数参数说明:
pattern : 匹配的正则表达式 string : 要匹配的字符串 flags : 标志位,用于控制正则表达式的匹配方式,如:是否区分大小写,多行匹配等等import re# 在起始位置匹配print(re.search("www","www.baidu.com").span())# 不在起始位置匹配print(re.search("com","www.baidu.com").span()) 打印结果:
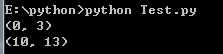
图3.png
我们可以使用group(num) 或 groups() 匹配对象函数来获取匹配表达式。
- group(num=0):匹配的整个表达式的字符串,group() 可以一次输入多个组号,在这种情况下它将返回一个包含那些组所对应值的元组。
- groups():返回一个包含所有小组字符串的元组,从 1 到 所含的小组号。
import reline = "Cats are smarter than dogs"searchObj = re.search(r"(.*) are (.*?) .*", line, re.M|re.I)if searchObj: print("searchObj.group(): ", searchObj.group()) print("searchObj.group(1): ", searchObj.group(1)) print("searchObj.group(2): ", searchObj.group(2)) passelse: print("Nothing found!") pass 打印结果:

图4.png
4). re.match与re.search的区别
re.match只匹配字符串的开始,如果字符串开始不符合正则表达式,则匹配失败,函数返回None;而re.search匹配整个字符串,直到找到一个匹配。5). 检索和替换
Python 的re模块提供了re.sub用于替换字符串中的匹配项。 语法:re.sub(pattern, repl, string, count=0)
参数:
pattern : 正则中的模式字符串。 repl : 替换的字符串,也可为一个函数。 string : 要被查找替换的原始字符串。 count : 模式匹配后替换的最大次数,默认 0 表示替换所有的匹配。repl为字符串示例:
import rephone = "2004-959-559 # 这个一个电话号码"# 删除注释num = re.sub(r'#.*$', "", phone)print("电话号码:", num)# 移除非数字内容num = re.sub(r'\D', "", phone)print("电话号码:", num) 打印结果:
图5.png
repl为函数示例:
# 将匹配的数字乘于2def double(matched): value = int(matched.group('value')) return str(value*2) passs = "A23G4HF56"print(re.sub("(?P \d+)", double, s)) 打印结果:

图6.png
6). compile 函数
compile 函数用于编译正则表达式,生成一个正则表达式( Pattern )对象,供 match() 和 search() 这两个函数使用。 语法格式为:re.compile(pattern[, flags])
参数:
pattern : 一个字符串形式的正则表达式 flags 可选,表示匹配模式,比如忽略大小写,多行模式等,具体参数为: 1> re.I 忽略大小写 2> re.L 表示特殊字符集 \w, \W, \b, \B, \s, \S 依赖于当前环境 3> re.M 多行模式 4> re.S 即为' . '并且包括换行符在内的任意字符(' . '不包括换行符) 5> re.U 表示特殊字符集 \w, \W, \b, \B, \d, \D, \s, \S 依赖于 Unicode 字符属性数据库 6> re.X 为了增加可读性,忽略空格和' # '后面的注释 示例:import re# 用于匹配至少一个数字pattern = re.compile(r'\d+')# 查找头部,没有匹配m = pattern.match('one12twothree34four')# 打印print(m)# 从‘e’的位置开始匹配,没有匹配m = pattern.match('one12twothree34four', 2, 10)print(m)# 从‘1’的位置开始匹配,正好匹配m = pattern.match('one12twothree34four', 3, 10)print(m)# group([group1, …]) 方法用于获得一个或多个分组匹配的字符串,当要获得整个匹配的子串时,可直接使用 group() 或 group(0);print(m.group(0))# start([group]) 方法用于获取分组匹配的子串在整个字符串中的起始位置(子串第一个字符的索引),参数默认值为 0;print(m.start(0))# end([group]) 方法用于获取分组匹配的子串在整个字符串中的结束位置(子串最后一个字符的索引+1),参数默认值为 0;print(m.end(0))# span([group]) 方法返回 (start(group), end(group))。print(m.span(0)) 打印结果:
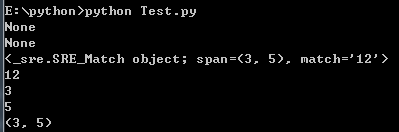
图7.png
7). findall
在字符串中找到正则表达式所匹配的所有子串,并返回一个列表,如果没有找到匹配的,则返回空列表。注意: match 和 search 是匹配一次 findall 匹配所有。 语法格式为:findall(string[, pos[, endpos]])
参数:
string 待匹配的字符串。 pos 可选参数,指定字符串的起始位置,默认为 0。 endpos 可选参数,指定字符串的结束位置,默认为字符串的长度。import re# 查找数字pattern = re.compile(r'\d+')result1 = pattern.findall('runoob 123 google 456')result2 = pattern.findall('runoob123google456', 0, 10)print(result1)print(result2) 打印结果:
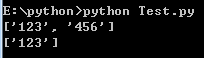
图8.png
8). finditer
和 findall 类似,在字符串中找到正则表达式所匹配的所有子串,并把它们作为一个迭代器返回。re.finditer(pattern, string, flags=0)
参数:
pattern : 匹配的正则表达式 string : 要匹配的字符串 flags : 标志位,用于控制正则表达式的匹配方式,如:是否区分大小写,多行匹配等等import reit = re.finditer(r"\d+","12a32bc43jf3")for match in it: print(match.group()) pass
打印结果:
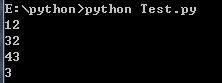
图9.png
2. CGI(Common Gateway Interface)
CGI(Common Gateway Interface),通用网关接口,它是一段程序,运行在服务器上如:HTTP服务器,提供同客户端HTML页面的接口。
1). 网页浏览 为了更好的了解CGI是如何工作的,我们可以从在网页上点击一个链接或URL的流程:- 1、使用你的浏览器访问URL并连接到HTTP web 服务器。
- 2、Web服务器接收到请求信息后会解析URL,并查找访问的文件在服务器上是否存在,如果存在返回文件的内容,否则返回错误信息。
-
3、浏览器从服务器上接收信息,并显示接收的文件或者错误信息。
CGI程序可以是Python脚本,PERL脚本,SHELL脚本,C或者C++程序等。 2). CGI架构图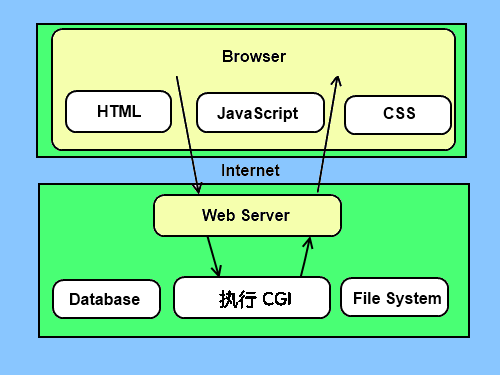 图10-CGI架构图
图10-CGI架构图3). 程序
#!D:\java\python\python.exe import cgi form=cgi.FieldStorage() name=form.getvalue('name','world') print """Content-type:text/html Greeting Page Hello.%s!
"""%name 转载地址:http://yfell.baihongyu.com/
你可能感兴趣的文章
如何重新注册VMware Update Manager(VUM)至vCenter Server中
查看>>
hdu1754
查看>>
vue前端页面跳转参数传递及存储
查看>>
使用Google Analytics跟踪下载等事件
查看>>
Netty服务器连接池管理设计思路
查看>>
5.多个Storyboard切换
查看>>
Vue CLI 3开发中屏蔽烦人的EsLint错误
查看>>
批量分发管理三种解决方案案例视频分享
查看>>
Scrum方法论(四)
查看>>
处理windows 2008x64平台exchange 2010 sp1打完系统补丁后,控制台无法打开
查看>>
Windows Server 2016-命令行Ntdsutil迁移FSMO角色
查看>>
征服Perl——基础知识——里程碑M4
查看>>
linux svn服务器搭建、客户端操作、备份与恢复
查看>>
报表服务入门(实验4)创建共享数据源
查看>>
程序员娶妻子的经典准则
查看>>
Synology NAS 存储系统多路径连接Vmware ESXi 6.5
查看>>
K8s 原理架构介绍(一)
查看>>
微软正式发布OneDrive 提供100GB免费空间
查看>>
移动端web无刷新上传图片【兼容安卓IOS】
查看>>
MySQL-MongoDB开源监控利器PMM增加slack报警功能
查看>>